
16. Where Are We Now?#
Kriti Sehgal and Amanda R. Kube Jotte
Part-1 of this textbook introduced you to the exciting field of Data Science and equipped you with the mathematical, statistical and programming tools to explore, clean, and understand data.
Let us look at where we are at through the lens of the Data Science Pipeline.
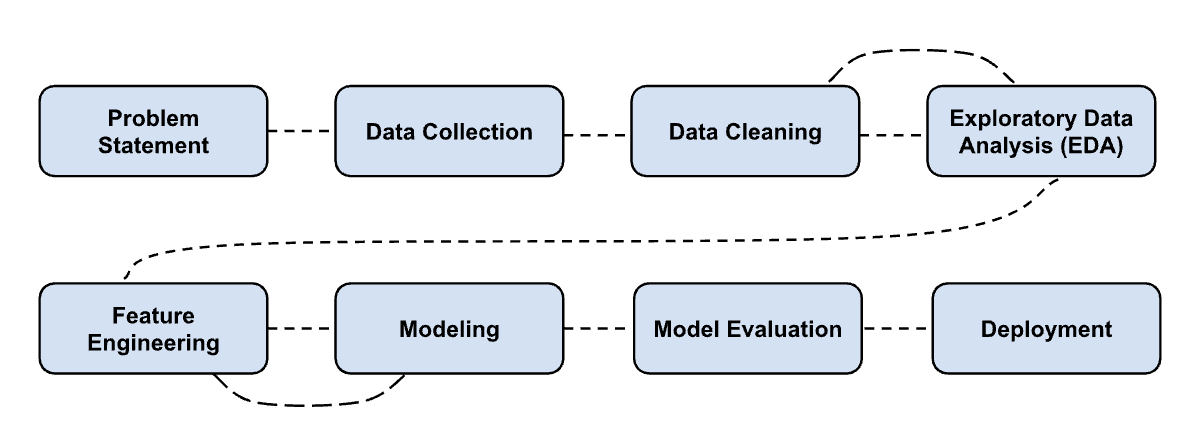
Figure: Data Science Pipeline.
So far, we have focused on the top line of this diagram. We’ve learned how to create, manipulate, and explore data as well as how to begin making statistical claims about data.
In Part II, we take the next step: use data to build models that help us make predictions, identify patterns, and uncover hidden structure. This is where we formally step into the world of machine learning.
We begin with the foundations of machine learning, building from regression and classification to modern approaches such as neural networks and tree models. Along the way, we develop essential skills in feature engineering, cross‑validation, clustering, and working with relational databases.
In this chapter, we will provide an introduction to the concept of prediction. Then, we will return to the topic of association to measure linear association using correlation. These topics will provide the background necessary to begin understanding and building your own prediction algorithms.